小报童精选导航站成果展示:
0x0
导航站的详细实操,讲了专栏来源的选择,如何整理获取专栏列表详情,前端样式怎么做,如何部署并生成最终的导航站等。
由于前端能力实在有限,所以本篇文章的重点是在如何获取精选的专栏列表上。
导航站使用一个开源项目改造而来。
小报童简介
小报童是个去中心化的课程平台。
创作者可以在小报童体面而用心的创作,专注创作,不搞套路。
而且专栏的价格大部分都比较便宜。
小报童官方不做社群,不做广告变现,不做算法推荐。
因为小报童是去中心化的,所以官网没有所有的专栏列表,只能通过专栏作者自发性的传播,或者小报童官方的推荐才能找到专栏地址。
所以有人就做了小报童的导航站,用来推荐专栏。
而且小报童这个不需要买专栏,就可以获得分销链接。所以理论上小报童的所有专栏都可以免费获得分销链接。
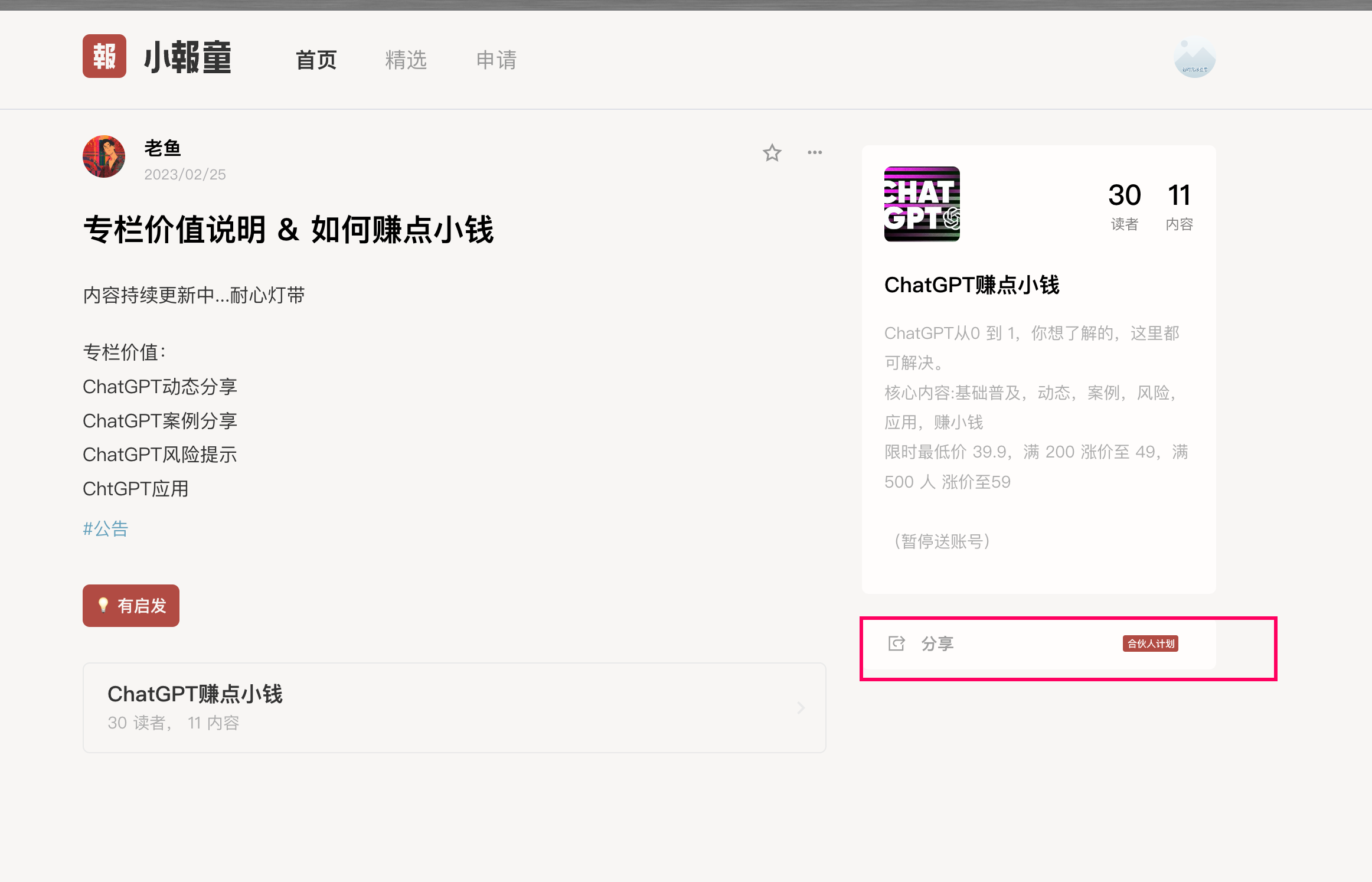
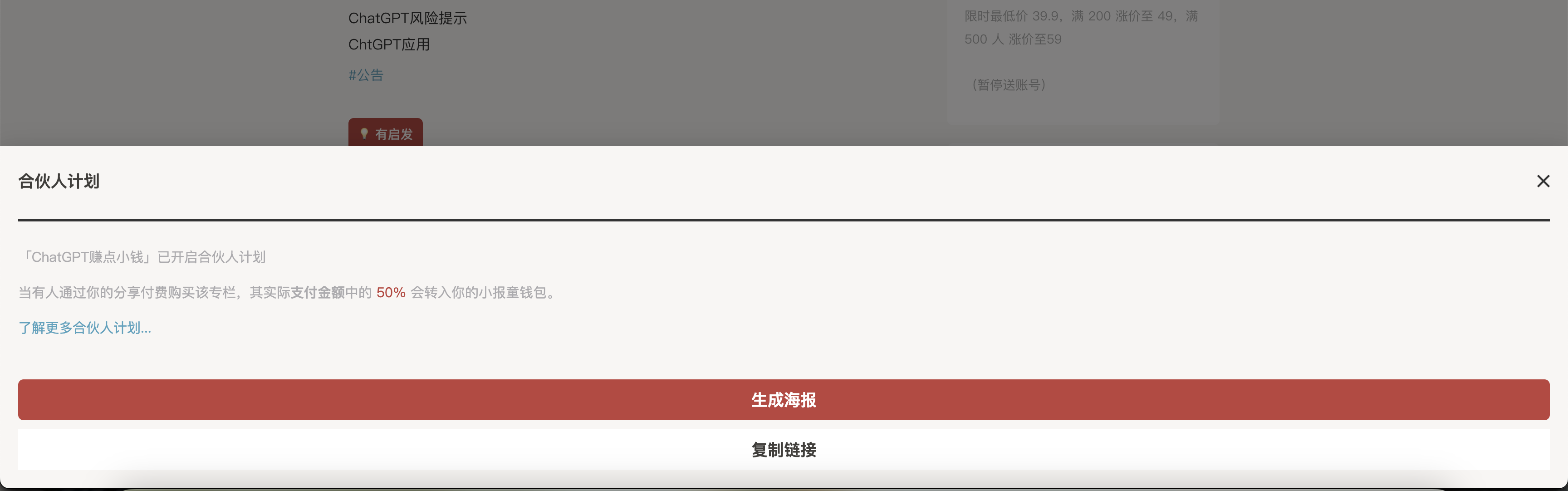
另外大声的吐槽一下,这样的专栏都是谁在买。
别人通过你的链接买了之后,你就可以获得分销收入。
但是吧,分销站这个东西,可能确实得有点私域流量才行,在pyq发分销的二维码,或者公众号发文章,或者自己的社群里发一下进行推荐。
单纯靠seo的话,目前排名比较靠前的seo做的都挺好的,新站感觉得做持久化运营搜索引擎排名才能上的去。
单搜小报童,官网占了整整一屏,下面的就是一些分销站了。
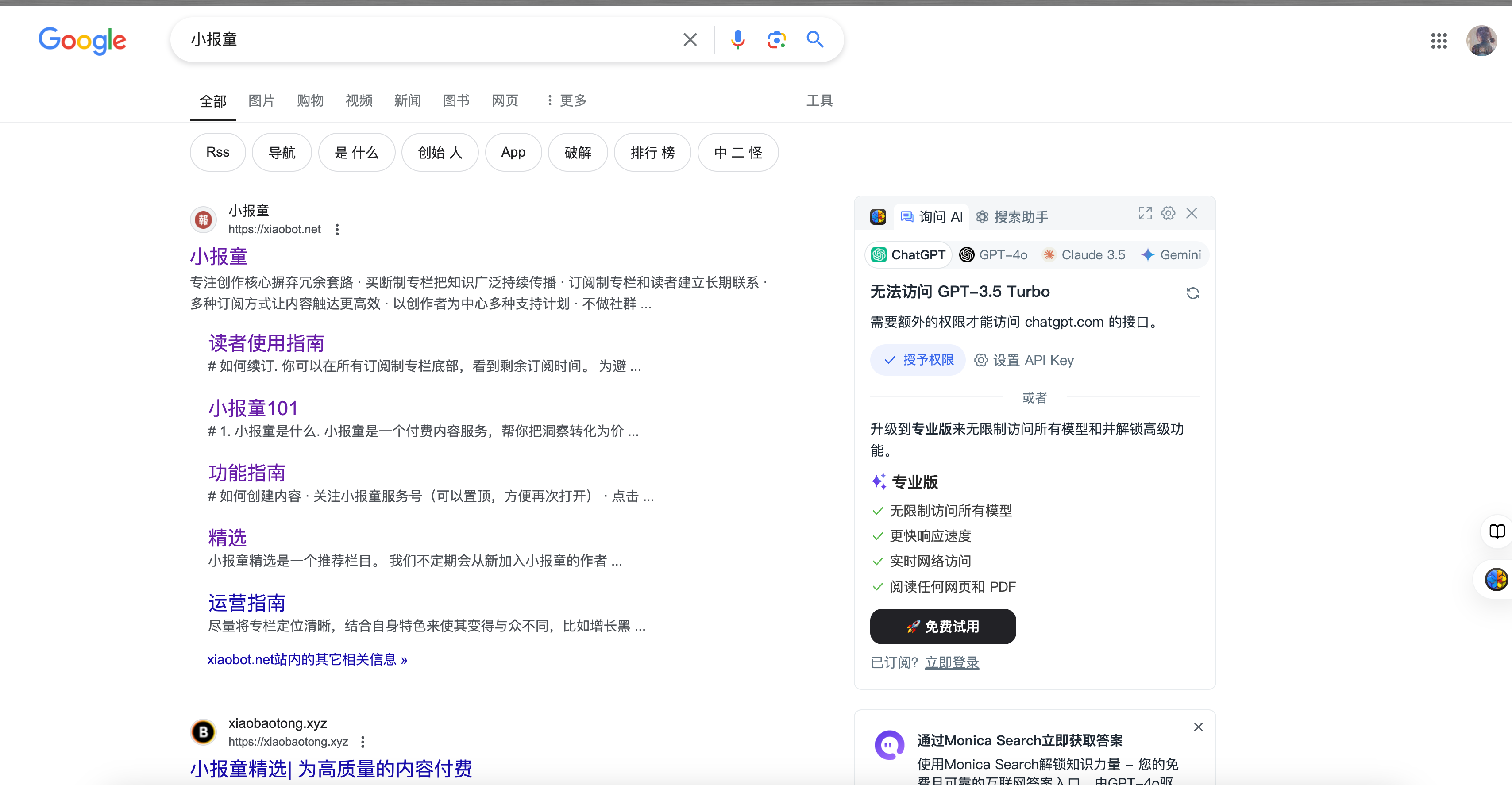
回到分销站,该如何从01到1做一个分销站出来。
我努力搜索,都没有搜索出一个可用的分销导航模板出来,有点点难。
数据源
做导航站首先要拿到数据,由于小报童的特殊性(去中心化),所以没法从官网得到所有专栏的数据。
可以选择从以下的几种渠道拿到数据
- 小报童精选公众号,里面会有一些精选专栏的推荐。
- pyq各种散落的专栏推荐
- 别人整理好的专栏列表
- 爬当前已有的小报童导航站的数据
小报童精选
小报童精选是小报童官方的公众号。
虽然是去中心化,但是一点入口都看不到,专栏的推广确实是会受阻。
所以有了小报童精选这个事。
精选文章每期会推荐一些有价值的专栏。所以精选是个获取专栏列表的路子。但是精选只能拿到一部分的专栏。
pyq
pyq加的一些人,会去推荐专栏,他们买了之后,会发他们自己的专属分销海报。
有时候我也会去通过他们的链接买一点,但是这种就是随缘,数量也不会太多。
别人整理好的专栏列表
我在网上冲浪的时候,发现了别人有一份整理好的专栏列表,但是这个可能会有时效性的问题,作者更新不及时,就拿不到增量的专栏列表。
下面这个就是一个民间的版本,上次更新还是在2年前。
https://github.com/qianguyihao/xiaobot-list?tab=readme-ov-file
爬当前已有的导航站的数据
这条路我感觉是最好的,多选几个导航站,把他们的专栏列表都爬一遍,然后去个重,就得到了最新最全的专栏列表了。
数据源的选择
上面介绍了几种数据来源,我这边选择的是爬小报童精选的推荐列表。其实更好的是去爬已有导航站的数据。
不过就精选专栏而言,官方的其实更好,毕竟官方已经做过一轮筛选了,能上推荐的肯定有其优点。
数据整理分类
选择好之后,我们就需要对推荐列表进行分类,订阅号里有目前所有的专栏推荐列表。截止到现在一共有26期。
对推荐列表进行整理就有2种方法。
- 人工整理
- 爬虫分类
26期的话,点开26条公众号文章,收集下所有的推荐专栏的二维码,倒也还好。
但是作为一个资深crud boy,能写代码就写代码。不能写代码,就让chatgpt帮我们写代码。
语言选择的是Java(资深java crud仔)。
选择的框架有如下几个
- Jsoup, 用于解析html
- Fastjson2,用于字符串转json处理
- Hutool,http&二维码识别
- selenium, 用于浏览器模拟,一些异步加载的页面需要用到这个
- commons-io,文件操作
下面就是实操了
如何拿到专栏推荐列表
首先是进入小报童精选 公众号的聊天页面,左下角有个往期回顾,这里就是推荐专栏的合集页面。

然后点击右上角,选择复制链接,或者选择使用默认浏览器打开,就可以拿到订阅列表的url
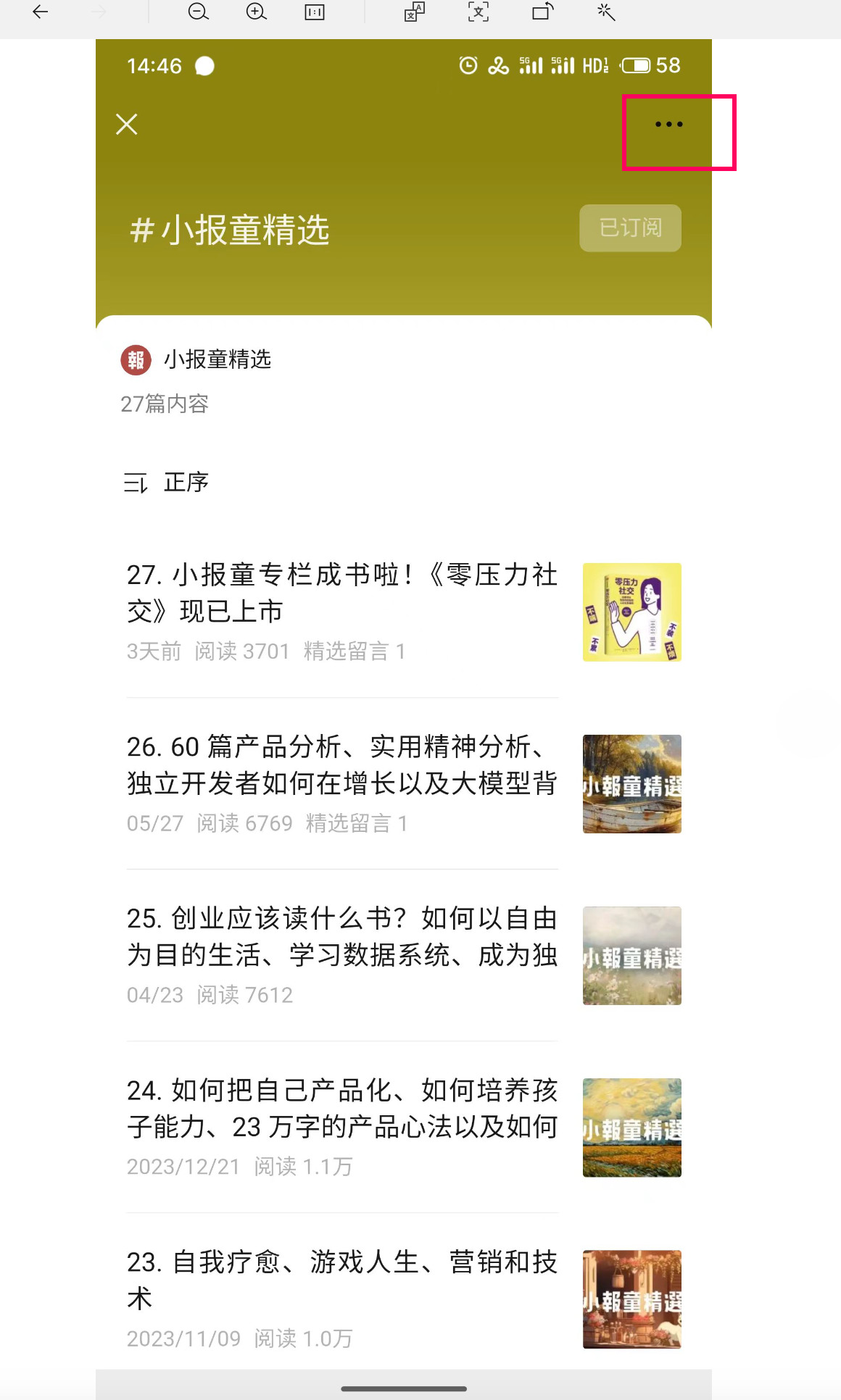
下面就是页面分析了,通过滑动页面猜测这个列表是分页加载的。
可以在控制台看网络请求,也可以看的出来。
uri中有一个关键的key,appmsgalbum, 这个看着像是列表的请求。经过测验,这个确实是分页参数。
浏览器地址栏的链接访问只能访问到第一页的页面。下面就要靠分页查询拿数据了。
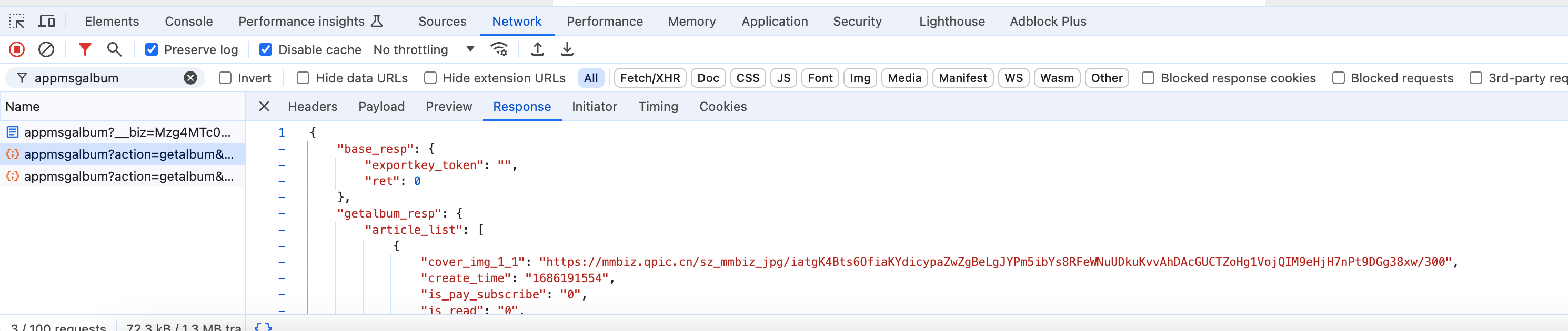
下面的分页请求返回的是json数据,第一页是html数据。
分页参数有2个比较关键的key,begin_msgid和begin_itemidx,这个一个是分页参数,一个是消息id,传入页数和id,查询下面的消息
这样的话就可以拿到所有的推荐文章的详细链接了。每一篇文章有一个专题推荐,包含数个专栏的推荐
经过页面元素审查以及debug,得到了如下获取订阅列表每篇文章地址的方法
常量类如下
public class Constants {
public static final String XIAOBOT_WECHAT_SUBSCRIBE_LIST_URL = "https://mp.weixin.qq.com/mp/appmsgalbum?action=getalbum&__biz=Mzg4MTc0MDcyOA==&scene=1&album_id=2262723582487429130&count=100&uin=&key=&devicetype=iMac+MacBookPro18%2C1+OSX+OSX+14.5+build(23F79)&version=13080811&lang=zh_CN&nettype=WIFI&ascene=0&fontScale=100";
public static final String LOCAL_CHROME_DRIVER_PATH = "/Users/since/Downloads/chromedriver-mac-arm64/chromedriver";
public static final String LIST_NEXT_URL_FORMAT = "https://mp.weixin.qq.com/mp/appmsgalbum?action=getalbum&__biz=Mzg4MTc0MDcyOA==&album_id=2262723582487429130&count=100&begin_msgid=%s&begin_itemidx=%s&uin=&key=&pass_ticket=&wxtoken=&devicetype=iMac MacBookPro18,1 OSX OSX 14.5 build(23F79)&clientversion=13080811&__biz=Mzg4MTc0MDcyOA==&appmsg_token=&x5=0&f=json";
}
获取订阅列表方法
import cn.hutool.http.HttpUtil;
import com.alibaba.fastjson2.JSON;
import com.alibaba.fastjson2.JSONArray;
import com.alibaba.fastjson2.JSONObject;
import com.thend03.xiaobot.spider.constants.Constants;
import com.thend03.xiaobot.spider.model.ArticleDetail;
import com.thend03.xiaobot.spider.model.WechatModel;
import org.apache.commons.collections4.CollectionUtils;
import org.apache.commons.lang3.StringUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Attributes;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.net.MalformedURLException;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
import java.util.Objects;
import java.util.stream.Collectors;
/**
* 小报童专栏精选订阅号列表解析服务
*
* @author since
* @date 2024-07-17 08:12
*/
public class WechatSubscribeListService {
public static List<ArticleDetail> parseArticleList() {
String content = HttpUtil.downloadString(Constants.XIAOBOT_WECHAT_SUBSCRIBE_LIST_URL, StandardCharsets.UTF_8);
Document parse = Jsoup.parse(content);
Elements albumListItem = parse.getElementsByClass("album__list-item");
System.out.println(1);
List<WechatModel> list = new ArrayList<>();
boolean hasNext = true;
for (Element element : albumListItem) {
Attributes attributes = element.attributes();
System.out.println(2);
if (attributes.isEmpty()) {
continue;
}
String s = attributes.get("data-msgid");
String s1 = attributes.get("data-itemidx");
String s2 = attributes.get("data-link");
String s3 = attributes.get("data-title");
String s4 = attributes.get("data-pos_num");
WechatModel wechatModel = new WechatModel();
wechatModel.setDataMsgId(parseLong(s));
wechatModel.setDataItemIndex(parseInt(s1));
wechatModel.setDataLink(s2);
wechatModel.setDataTitle(s3);
wechatModel.setDataPosNum(parseInt(s4));
list.add(wechatModel);
if (wechatModel.getDataPosNum() == 1) {
hasNext = false;
}
}
while (hasNext) {
List<WechatModel> list1 = nextParse(list.get(list.size() - 1));
if (CollectionUtils.isNotEmpty(list1)) {
list.addAll(list1);
}
if (list1.get(list1.size() - 1).getDataPosNum() == 1) {
hasNext = false;
}
}
List<String> urlList = new ArrayList<>();
list.stream().filter(Objects::nonNull).forEach(s -> {
List<String> urlList1 = WechatDetailService.getUrlList(s.getDataLink());
if (CollectionUtils.isNotEmpty(urlList1)) {
urlList.addAll(urlList1);
}
});
List<String> collect = urlList.stream().filter(StringUtils::isNotBlank).filter(s -> s.contains("http") && s.contains("xiaobot.net/p")).map(s -> {
String[] split = s.split("\\?");
return split[0];
}).distinct().collect(Collectors.toList());
List<ArticleDetail> collect1 = collect.stream().filter(Objects::nonNull).map(url -> {
String host = null;
String uniqueId = null;
try {
host = WechatDetailService.getHost(url);
} catch (MalformedURLException e) {
}
try {
uniqueId = WechatDetailService.getArticleUniqueId(url);
} catch (MalformedURLException e) {
throw new RuntimeException(e);
}
return WechatDetailService.getArticleDetail(host, uniqueId);
}).collect(Collectors.toList());
return collect1;
}
public static long parseLong(String dataMsgId) {
try {
return Long.parseLong(dataMsgId);
} catch (Exception e) {
e.printStackTrace();
}
return -1;
}
public static int parseInt(String itemIndex) {
try {
return Integer.parseInt(itemIndex);
} catch (Exception e) {
e.printStackTrace();
}
return -1;
}
public static List<WechatModel> nextParse(WechatModel wechatModel) {
List<WechatModel> list = new ArrayList<>();
String format = String.format(Constants.LIST_NEXT_URL_FORMAT, wechatModel.getDataMsgId(), wechatModel.getDataItemIndex());
String content = HttpUtil.downloadString(format, StandardCharsets.UTF_8);
JSONObject jsonObject = JSON.parseObject(content);
JSONObject getalbumResp = jsonObject.getJSONObject("getalbum_resp");
JSONArray articleList = getalbumResp.getJSONArray("article_list");
for (int i = 0; i < articleList.size(); i++) {
Object o = articleList.get(i);
if (o instanceof JSONObject) {
JSONObject json = (JSONObject) o;
long msgid = json.getLongValue("msgid");
int itemidx = json.getIntValue("itemidx");
int posNum = json.getIntValue("pos_num");
String title = json.getString("title");
String link = json.getString("url");
WechatModel nextWechatModel = new WechatModel();
nextWechatModel.setDataMsgId(msgid);
nextWechatModel.setDataItemIndex(itemidx);
nextWechatModel.setDataLink(link);
nextWechatModel.setDataTitle(title);
nextWechatModel.setDataPosNum(posNum);
list.add(nextWechatModel);
}
}
return list;
}
}
如何拿到专栏地址
在上一步 我们拿到了26篇精选推荐的文章地址列表,这一步我们需要解析每一篇文章详情,拿到这一批推荐的专栏合集。
每一篇文章里都会推荐1~N篇文章,数量不等。
我拿几篇文章分析了一下,每篇文章的专栏没有特定的标签,但是由于是公众号文章,所以专栏都是以图片二维码的形式提供的。
即能拿到所有的专栏二维码图片即可。
以 序号26的这篇文章为例
推荐的专栏以文字介绍+二维码的图片格式提供出来。
这篇文章一共推荐了4个专栏,理论上我们拿到这4个专栏的图片二维码就可以了。

打开浏览器的控制台,进行元素审查,在img标签里的data-src字段可以拿到图片地址
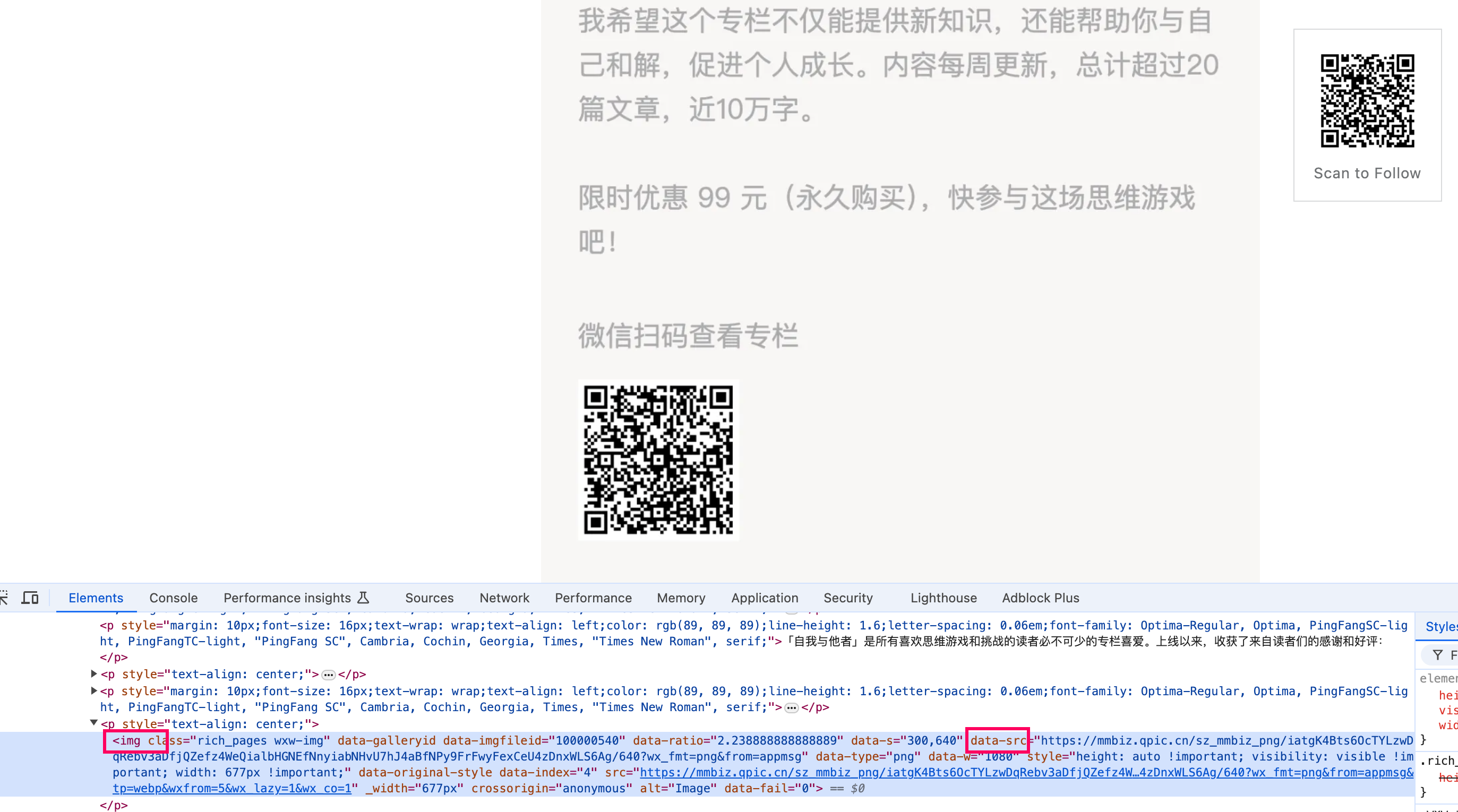
现在的获取图片地址的方法过于生硬了,需要从script里解析变量重重硬解析才能拿到图片地址
List<String> result = new ArrayList<>();
String content = HttpUtil.downloadString(wechatUrl, StandardCharsets.UTF_8);
Document parse = Jsoup.parse(content);
Elements scripts = parse.getElementsByTag("script");
for (Element script : scripts) {
List<Node> nodes = script.childNodes();
for (Node node : nodes) {
if (node instanceof DataNode) {
DataNode dataNode = (DataNode) node;
String wholeData = dataNode.getWholeData();
if (wholeData.contains("cdn_url")) {
String[] split = wholeData.split("var");
for (int i = 0; i < split.length; i++) {
String s = split[i];
if (s.contains("picturePageInfoList") && s.contains("http")) {
String[] split1 = s.split("picturePageInfoList");
String cdnUrl = split1[1];
String s1 = cdnUrl.replaceAll("\\[", "")
.replaceAll("]", "")
.replaceAll("\\{", "")
.replaceAll("}", "")
.replaceAll("'", "")
.replaceAll("\"", "");
String[] split2 = s1.split(",");
for (int j = 0; j < split2.length; j++) {
if (split2[j].contains("cdn_url")) {
String[] split3 = split2[j].split("cdn_url:");
result.add(split3[1]);
}
}
}
}
}
}
}
}
其实换个方法,一句话就可以提取所有图片地址了, 使用select方法,标签+属性即可。
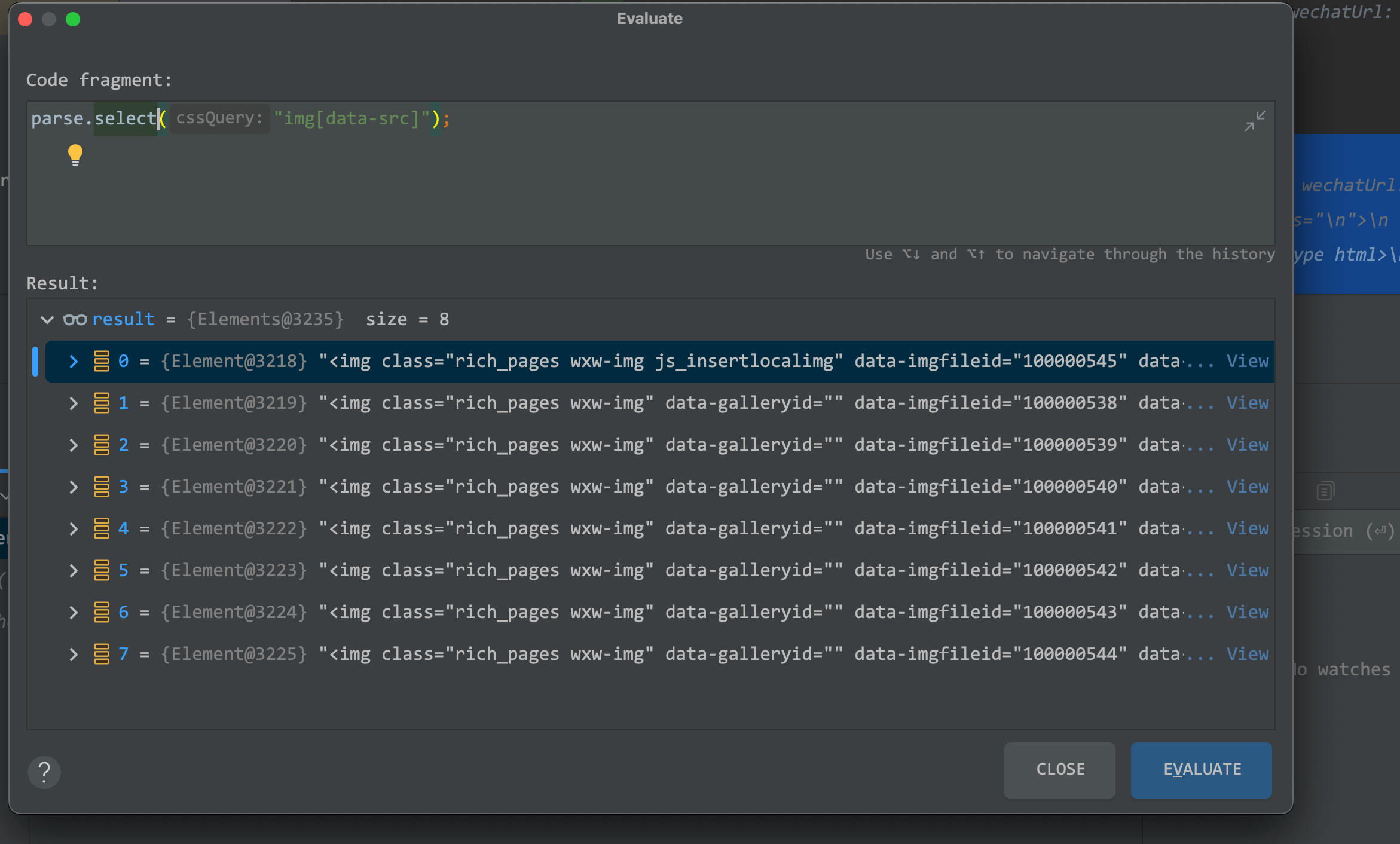
拿到图片地址之后,使用hutool进行二维码识别,报错了就忽略异常,有二维码的能成功解析,能正常解析的就是二维码地址了。
public static String hutoolOcr(String imageUrl) throws IOException, URISyntaxException {
String finalUrl = "";
File file = HttpUtil.downloadFileFromUrl(imageUrl, "static/" + COUNT.getAndIncrement() + ".png");
try {
finalUrl = QrCodeUtil.decode(file);
} catch (Exception e) {
e.printStackTrace();
}
return finalUrl;
}
这样就拿到每期精选的所有的推荐专栏列表了
如何获取专栏的详情
拿到专栏地址之后,就是去处理专栏了,我们上一步拿到的只是专栏的地址,专栏标题、作者、专栏头像、专栏介绍、专栏的已购数、文章数,都需要从专栏里获取。
打开控制台,这几个接口把所有的数据都返回了,且返回的是json数据,所以看着很美好。
但是这几个接口都是要签名的,整个页面是异步加载的,无法使用jsoup进行解析。而且也不知道签名规则,所以这条路行不通。
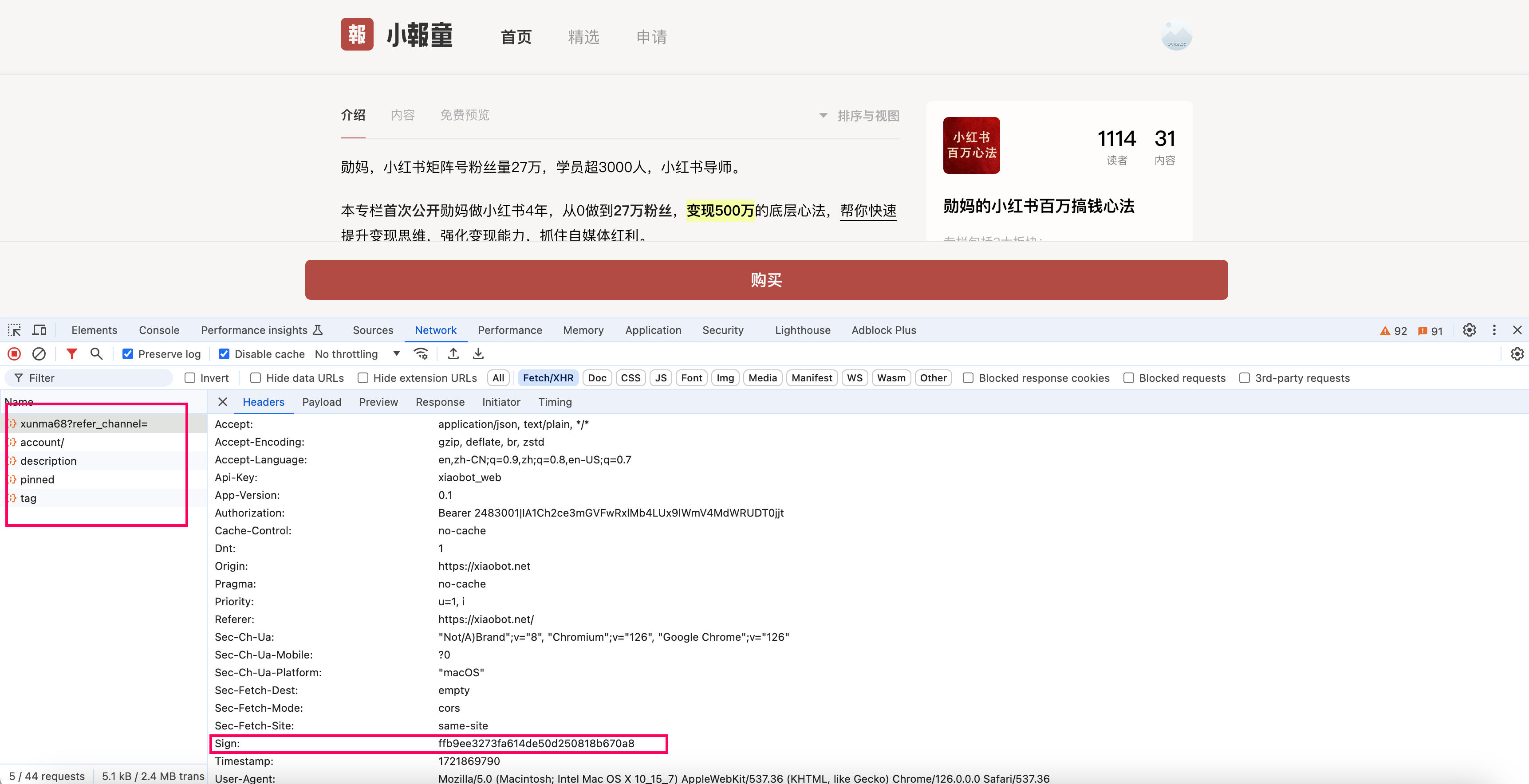
后来经过一番搜索,可以使用selenium模拟浏览器,等待页面异步加载完成,这样就可以使用jsoup解析页面了。
使用selenium需要在下载chrome驱动到本地,chrome驱动需要和自己的chrome浏览器版本相等或相近,版本不要差太多。
114之前的版本在https://chromedriver.storage.googleapis.com/index.html下载
127之后的版本在https://googlechromelabs.github.io/chrome-for-testing/下载
115-126的暂时没找到,随着时间推移,这个最新的版本也可能会发生变化
记得是下载chromedriver
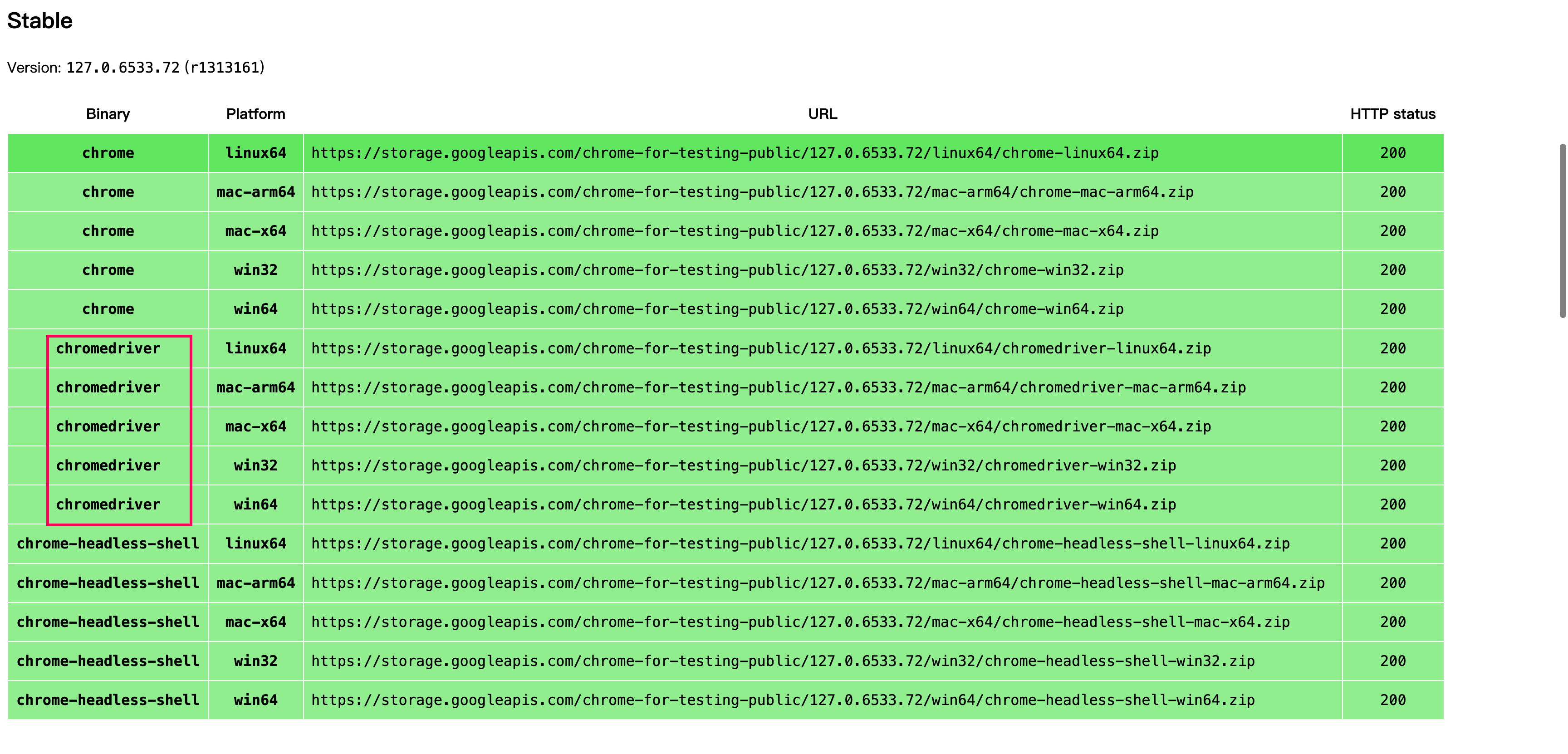
拿到driver之后,就可以使用代码模拟浏览器的页面异步加载过程,得到完整的页面了,然后就可以使用jsoup解析页面元素
public static String getArticleFullPage(String url) {
// 设置 ChromeDriver 路径
System.setProperty("webdriver.chrome.driver", Constants.LOCAL_CHROME_DRIVER_PATH);
// 设置 Chrome 选项
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless"); // 无头模式
// 启动 Chrome 浏览器
WebDriver driver = new ChromeDriver(options);
// 访问目标网页
driver.get(url);
String pageContent = null;
// 等待网页加载完成(根据需要调整等待时间)
try {
Thread.sleep(2000);
// 获取网页内容
pageContent = driver.getPageSource();
// 打印网页内容
System.out.println(pageContent);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
driver.quit();
}
return pageContent;
}
整体解析文章详情的方法如下
public static ArticleDetail getArticleDetail(String host, String uniqueId) {
String url = "https://" + host + "/p/" + uniqueId;
String articleFullPage = getArticleFullPage(url);
Document document = Jsoup.parse(articleFullPage);
Elements title = document.getElementsByTag("title");
Elements intro = document.getElementsByClass("intro");
Elements description = document.getElementsByClass("description");
Elements posts = document.getElementsByClass("posts");
Elements elementsByClass = document.getElementsByClass("paper");
Elements num = document.getElementsByClass("num");
Elements avatar = document.getElementsByClass("avatar");
String articleTitle = getArticleTitle(title);
String articleDescription = getArticleDescription(description);
String articleIntro = getArticleIntro(intro);
Map<String, Integer> articleNum = getArticleNum(num);
String articleAvatar = getArticleAvatar(avatar);
ArticleDetail articleDetail = new ArticleDetail();
articleDetail.setAvatarBase64(articleAvatar);
// articleDetail.setGmtCreate(createdAt);
articleDetail.setIntroduction(articleIntro);
// articleDetail.setFreePostCount(freePostCount);
articleDetail.setPostCount(articleNum.get("post"));
articleDetail.setTitle(articleTitle);
articleDetail.setSubscriberCount(articleNum.get("reader"));
articleDetail.setUrl(url);
System.out.println(1);
return articleDetail;
}
public static String getHost(String articleUrl) throws MalformedURLException {
java.net.URL url = new URL(articleUrl);
return url.getHost();
}
public static String getArticleUniqueId(String articleUrl) throws MalformedURLException {
java.net.URL url = new URL(articleUrl);
String path = url.getPath();
return path.replaceAll("/p/", "");
}
public static String getArticleFullPage(String url) {
// 设置 ChromeDriver 路径
System.setProperty("webdriver.chrome.driver", Constants.LOCAL_CHROME_DRIVER_PATH);
// 设置 Chrome 选项
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless"); // 无头模式
// 启动 Chrome 浏览器
WebDriver driver = new ChromeDriver(options);
// 访问目标网页
driver.get(url);
String pageContent = null;
// 等待网页加载完成(根据需要调整等待时间)
try {
Thread.sleep(2000);
// 获取网页内容
pageContent = driver.getPageSource();
// 打印网页内容
System.out.println(pageContent);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
driver.quit();
}
return pageContent;
}
/**
* 专栏的标题
* @param title title element
* @return title
*/
public static String getArticleTitle(Elements title) {
if (Objects.isNull(title)) {
return null;
}
if (title.isEmpty()) {
return null;
}
List<String> result = new ArrayList<>();
for (Element element : title) {
List<Node> nodes = element.childNodes();
if (CollectionUtils.isEmpty(nodes)) {
continue;
}
List<String> collect = nodes.stream().filter(Objects::nonNull).map(node -> {
if (node instanceof TextNode) {
return ((TextNode) node).text();
}
return null;
}).collect(Collectors.toList());
result.addAll(collect);
}
return StringUtils.join(result, ",");
}
public static String getArticleDescription(Elements description) {
if (Objects.isNull(description)) {
return null;
}
if (description.isEmpty()) {
return null;
}
List<String> result = new ArrayList<>();
Iterator<Element> iterator = description.iterator();
while (iterator.hasNext()) {
Element next = iterator.next();
List<String> list = parseNode(next);
result.add(StringUtils.join(list, ""));
}
String join = StringUtils.join(result, "");
return join.replaceAll("<p></p>", "\r\n\n");
}
public static String getArticleIntro(Elements intro) {
if (Objects.isNull(intro)) {
return null;
}
if (intro.isEmpty()) {
return null;
}
List<String> result = new ArrayList<>();
for (Element next : intro) {
List<String> list = parseNode(next);
result.add(StringUtils.join(list, ""));
}
String join = StringUtils.join(result, "");
return join.replaceAll("<br>", "\r\n");
}
public static Map<String, Integer> getArticleNum(Elements num) {
if (Objects.isNull(num)) {
return Collections.emptyMap();
}
if (num.isEmpty()) {
return Collections.emptyMap();
}
Element reader = num.get(0);
Element post = num.get(1);
TextNode node = (TextNode) reader.childNodes().get(0);
String text = node.text();
TextNode postNode = (TextNode) post.childNodes().get(0);
String text1 = postNode.text();
Map<String, Integer> map = new HashMap<>(4);
map.put("reader", Integer.parseInt(text));
map.put("post", Integer.parseInt(text1));
return map;
}
public static String getArticleAvatar(Elements avatar) {
if (Objects.isNull(avatar)) {
return null;
}
if (avatar.isEmpty()) {
return null;
}
Element element = avatar.get(0);
String avatarUrl = element.attributes().get("src");
byte[] bytes = HttpUtil.downloadBytes(avatarUrl);
return "data:image/jpeg;base64," + Base64.getEncoder().encodeToString(bytes);
}
/**
* 解析node详情,需要递归,text node/element
* @param element element
* @return list
*/
public static List<String> parseNode(Element element) {
if (Objects.isNull(element)) {
return null;
}
List<Node> nodes = element.childNodes();
if (CollectionUtils.isEmpty(nodes)) {
return null;
}
List<String> result = new ArrayList<>();
for (Node node : nodes) {
List<Node> textNodeList = node.childNodes();
if (CollectionUtils.isEmpty(textNodeList)) {
if (node instanceof TextNode) {
result.add(((TextNode) node).text());
} else {
result.add(node.toString());
}
continue;
}
List<String> subList = new ArrayList<>();
for (Node text : textNodeList) {
if (Objects.isNull(text)) {
continue;
}
if (text instanceof TextNode) {
subList.add(((TextNode) text).text());
} else if (text instanceof Element) {
List<String> list = parseNode((Element) text);
if (CollectionUtils.isNotEmpty(list)) {
subList.add(StringUtils.join(list, ""));
}
} else {
subList.add(text.toString());
}
}
result.add(StringUtils.join(subList, ""));
}
return result;
}
前端页面展示
由于我是前端废,找了个开源的导航项目当模板,找我的前端朋友改了一下。
开源项目地址如下: https://github.com/jic999/moon-web-start
经过修改的前端项目地址如下: https://github.com/gloaming123/moon-web-start
后端代码项目地址如下: https://github.com/thend03/xiaobot-spider
这个导航项目自动github pages部署,可以直接在仓库的actions点击运行,可以在job的运行日志里得到页面访问地址。
为了优化加载速度,我这边生成的详情,将专栏的头像转成了base64,前端再将base64转成本地图片,优化了加载速度。
总结
经过一系列的勾兑,就拿到了专栏的详情。
总得来说,后端就是使用了http+jsoup解析了页面,没有什么难的。对api熟悉的话速度会更快一点。
没有涉及大规模的爬虫,算是一次简单的尝试吧。
对我来说难的果然还是前端呀,需要我的前端合伙人持续发力,实现前端页面了。
前端地址,那个专属分销码需要自己替换,由于我不懂前端,没法给出详细的使用说明,我自己的分销码是我的前端朋友帮我专门写到一个分支里了。
另外爬精选列表,只能拿到部分上推荐的专栏,其他不在推荐里的,要么去其他的导航站爬,要么靠其他散落的地方传播了。
小报童的专栏价格都不大贵,适合当知识付费的小册来购买,有的可以来点启发我觉得就能值回票价了。